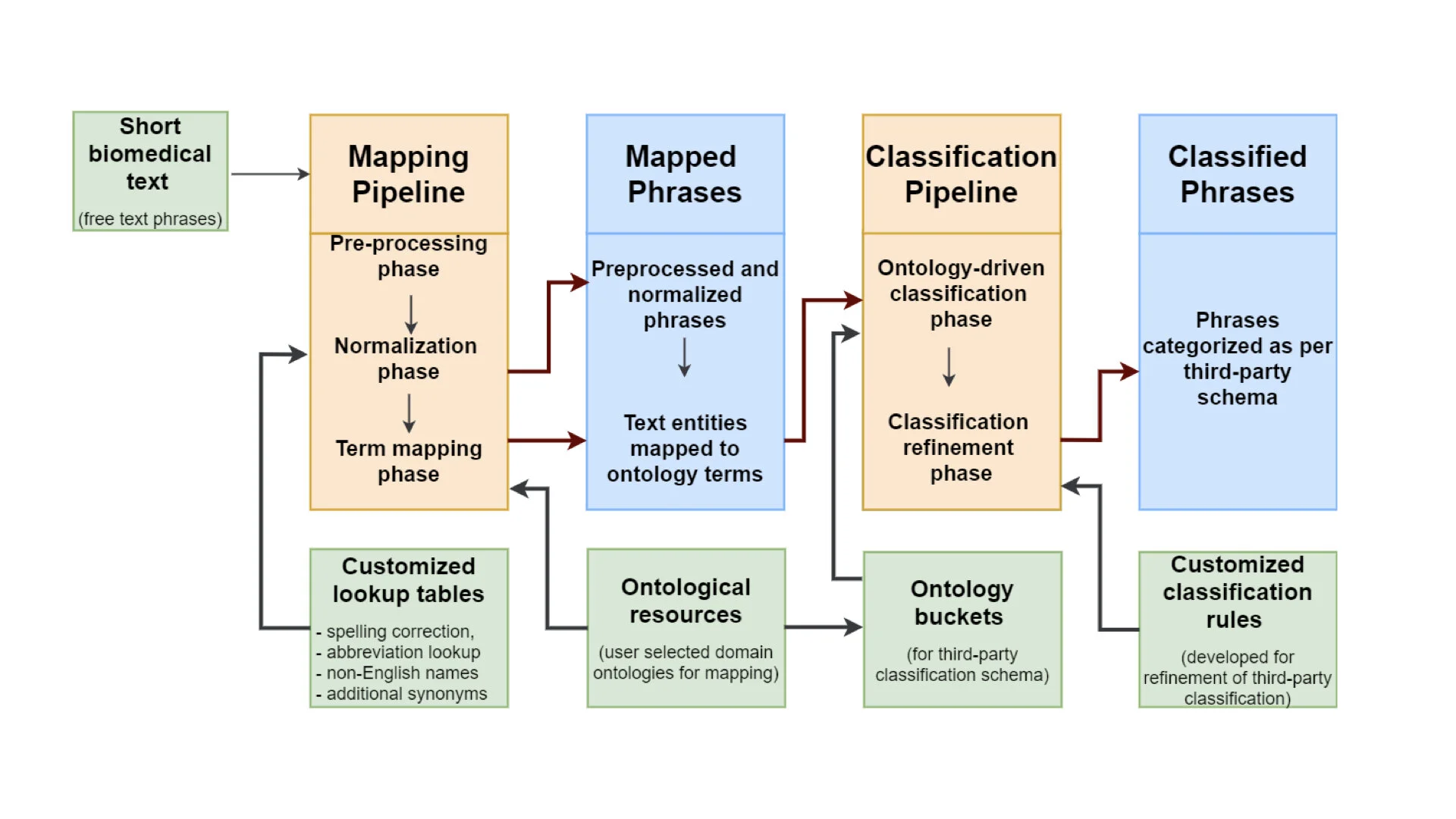
The final blog in our series on text-mining is a guest blog written by Shyama Saha, who specialises in Machine Learning/Text Mining at EMBL-EBI. The CINECA project aims to create a text mining tool suite to support extraction of metadata concepts from unstructured textual cohort data and description files. To create a standardised metadata representation CINECA is using Natural language processing (NLP) techniques such as entity recognition, using rule-based tools such as MetaMap, LexMapr, and Zooma. In this blog Shyama discusses the challenges of dictionary and rule-based text-mining tools, especially for entity recognition tasks, and how deep learning methods address these issues.
Read More